Make es una plataforma online de automatización de procesos que se describe como «el pegamento de Internet». Esto se debe a que permite «conectar» numerosas aplicaciones para que trabajen de manera integrada y compartan datos entre ellas.
¿Cuántas personas en el mundo saben leer, escribir y contar? Se calcula que aproximadamente el 86%. Pero, ¿cuántas personas saben programar? Apenas un 0.4%. Con Make, puedes realizar automatizaciones sin necesidad de programar.
Mi objetivo con este manual detallado es proporcionarte los conocimientos para que puedas aprender como usar Make. Desde junio de 2023, he trabajado como consultor de inteligencia artificial y automatización para empresas.
¿Cómo puedo ayudarte a conseguir más clientes online?
- A corto plazo (Publicidad en Google, Facebook, e Instagram).
- A medio plazo (SEO local).
- A largo plazo (Posicionó tu web).
- Diseño página web, tienda online o landing page, si es necesario.
- Herramientas de seguimiento y medición.
- Diversificación: Marketing de contenidos, mail marketing, redes sociales, alta en directorios, etc.
- Automatiza con IA: Optimiza tareas y aumenta tu productividad. Certificación Máster IA by BIG School

¿Qué es una automatización?
Una automatización se refiere al uso de herramientas o tecnologías que minimizan la intervención humana en la ejecución de tareas o procesos. Al automatizar una tarea, se busca que una máquina o sistema informático la ejecute de manera automática, sin que sea necesario que una persona la realice manualmente.
Beneficios de la automatización:
Las automatizaciones brindan una variedad de beneficios que impactan positivamente en la eficiencia, productividad y rentabilidad de las empresas, así como en la vida cotidiana de las personas.
Algunos de los beneficios más destacados son:
- Precisión y eficiencia: Las máquinas y sistemas automatizados pueden llevar a cabo tareas con mayor precisión y eficiencia que los humanos, ya que no están expuestos a errores causados por cansancio, distracciones o falta de atención.
- Optimización de recursos y tiempo: Al liberar a las personas de tareas repetitivas y rutinarias, la automatización permite un mejor uso de los recursos y del tiempo, permitiendo que se dediquen a actividades más estratégicas y creativas.
- Reducción de errores: La automatización disminuye notablemente la posibilidad de errores humanos, dado que los sistemas automatizados siguen instrucciones predefinidas de forma consistente y precisa.
- Menos costes: La automatización puede ayudar a reducir los costes operativos al disminuir la necesidad de mano de obra para tareas rutinarias, acelerar procesos y minimizar errores que podrían generar gastos adicionales.
Ejemplo de automatización con Make:
Puedes tener una hoja de cálculo en Google Sheets con la información de tus clientes, de modo que cada vez que realices un cambio, se ejecuten automáticamente tareas en el ERP, se envíe un correo al responsable del cliente y se envíe un WhatsApp al cliente una hora después del cambio.
Automatizaciones «no code»
Existen dos enfoques principales para implementar la automatización:
- Automatización con código y programación: Este método tradicional requiere aprender un lenguaje de programación específico y un complejo proceso de implementación, que incluye la configuración de computadoras y servidores dedicados.
- Automatización sin código (No-Code): Este enfoque innovador se basa en plataformas preconstruidas que permiten automatizar tareas sin necesidad de escribir código. Las plataformas No-Code ofrecen una interfaz visual e intuitiva, facilitando su aprendizaje y aplicación, incluso para personas sin experiencia en programación. Una herramienta no-Code es Make.com.
Automatización con código:
-> Ventajas:
- Control total: La automatización con código brinda un control absoluto sobre el proceso y la integración de sistemas.
- Personalización avanzada: Permite crear soluciones altamente personalizadas para casos específicos y complejos.
- Escalabilidad: Las soluciones basadas en código son ideales para proyectos que requieren escalar a un gran volumen de usuarios.
-> Desventajas:
- Complejidad y dificultad: Requiere un conocimiento profundo de programación y un equipo especializado.
- Costes elevados: El desarrollo con código suele ser más costoso debido a la necesidad de contratar programadores especializados.
- Tiempos de desarrollo largos: La implementación de soluciones con código puede llevar meses.
Automatización con No-Code:
-> Ventajas:
- Facilidad de uso: Las plataformas No-Code son simples de aprender y utilizar, incluso sin experiencia previa en programación.
- Rapidez en la implementación: El enfoque No-Code permite desarrollar soluciones en días o semanas, en contraste con los meses que puede requerir la programación tradicional.
- Costes reducidos: El No-Code es más económico, ya que no es necesario contratar un equipo de desarrollo especializado.
-> Desventajas:
- Limitaciones en la personalización: Las plataformas No-Code pueden presentar restricciones en cuanto a la personalización de las soluciones.
- Dependencia de la plataforma: Las soluciones No-Code dependen de la plataforma seleccionada, lo que puede generar problemas si esta deja de existir o cambia sus políticas.
Lógica de programación en plataformas no-code
A pesar de la interfaz visual, las bases de la programación siguen siendo las mismas. Necesitamos comprender los conceptos de secuencialidad, flujo de control, variables y condicionales para aplicar correctamente el No-Code.
Para poder aplicar el No-Code de forma efectiva, debemos entender los siguientes conceptos clave:
- Secuencialidad: La secuencialidad se refiere al orden en que se ejecutan las acciones en un programa. Los ordenadores procesan las instrucciones paso a paso, en un orden predeterminado. Cómo veremos más adelante Make ejecuta las órdenes de Izquierda a derecha
- Variables: Las variables son espacios en la memoria del ordenador que almacenan información para ser utilizada por la automatización. Por ejemplo, cada celda de Google Sheets son variables.
- Tipos de datos: Los tipos de datos se refieren a las diferentes categorías de información que se pueden almacenar en una variable. Es importante definir el tipo de dato correcto para cada variable, ya que esto determina cómo se procesa la información. Los tipos de variables suelen ser: Números, textos, Arrays (agrupan diferentes grupos de variables) o Booleanos (Se almacena Verdadero O Falso).
- Condiciones: Los condicionales son herramientas que nos permiten controlar el flujo de trabajo de una automatización. Permiten definir caminos alternativos de ejecución, dependiendo de si se cumple o no una condición. Los tipos más comunes son, igual, mayor, menor, AND u OR. Por ejemplo, si recorremos una lista de emails podemos solo mandar un saludo a todos aquellos que sean iguales a gmail.com O (OR) que sean de outlook.
- Bucles: Los bucles son herramientas que permiten repetir una acción o un conjunto de acciones un número determinado de veces o hasta que se cumpla una condición. Son muy útiles para automatizar tareas repetitivas. Podemos querer recorrer una lista hasta encontrar un email en concreto.
¿Qué es Make?
Make es una poderosa herramienta de automatización que permite conectar diferentes aplicaciones y servicios online. Con Make, puedes crear flujos de trabajo personalizados para automatizar tareas repetitivas y mejorar la eficiencia de tus procesos.
Cómo funciona y darse alta
Make funciona conectando diferentes aplicaciones a través de «escenarios». Estos escenarios son como rutas que indican a Make qué acciones realizar en un orden específico.
Por ejemplo, un vendedor podría usar Make para automatizar el envío de correos electrónicos de seguimiento a clientes potenciales después de una reunión.
Para comenzar a utilizar Make, necesitamos crear una cuenta gratuita. El proceso es
sencillo y rápido:
- Acceso a la plataforma Make.com: Ingresamos a la página web de Make (Make.com).
- Aceptación de cookies: Aceptamos las cookies del sitio para continuar.
- Opción «Get Started Free»: Hacemos clic en «Get Started Free» para comenzar el registro gratuito.
- Formulario de registro: Rellenamos el formulario con nuestro nombre, correo electrónico, contraseña, región y país.
- Inicio de sesión con Google, Facebook o GitHub: También podemos registrarnos usando nuestras cuentas de Google, Facebook o GitHub.
- Verificación de cuenta por correo electrónico: Recibimos un correo para verificar la cuenta una vez registrados.
Al iniciar sesión por primera vez, Make solicitará que completemos un breve formulario con información sobre nuestro rol laboral, el tamaño de nuestra organización y cómo conocimos la plataforma. Estos datos ayudarán a Make a personalizar nuestra experiencia.
Tipos de suscripciones de Make
Make ofrece varios planes de suscripción que se adaptan a las necesidades de cada usuario:
Plan gratuito: Ideal para quienes están empezando a explorar la plataforma. Incluye 1,000 operaciones mensuales, permite crear escenarios sin código, acceso a más de 1,000 aplicaciones estándar, usuarios ilimitados, 2 escenarios activos, tiempo de ejecución de 5 minutos por escenario, intervalos de 15 minutos entre ejecuciones, archivos de hasta 5 MB y la opción de crear aplicaciones personalizables.
Plan core (9 €/mes): Ofrece 10,000 operaciones al mes, escenarios activos ilimitados, 40 minutos de ejecución por escenario, archivos de hasta 100 MB, intervalos de 1 minuto entre escenarios, acceso a más de 300 APIs de Make y la capacidad de crear aplicaciones personalizables.
Plan pro (16 €/mes): Incluye 10,000 operaciones mensuales, archivos de hasta 250 MB y prioridad en la ejecución de escenarios.
Plan teams (29 €/mes): Diseñado para organizaciones con múltiples usuarios que requieren colaboración en la creación de automatizaciones. Permite asignar proyectos y roles específicos a cada miembro del equipo.
Plan enterprise: Solución personalizada para grandes empresas con necesidades avanzadas de automatización.
Primeros pasos con Make
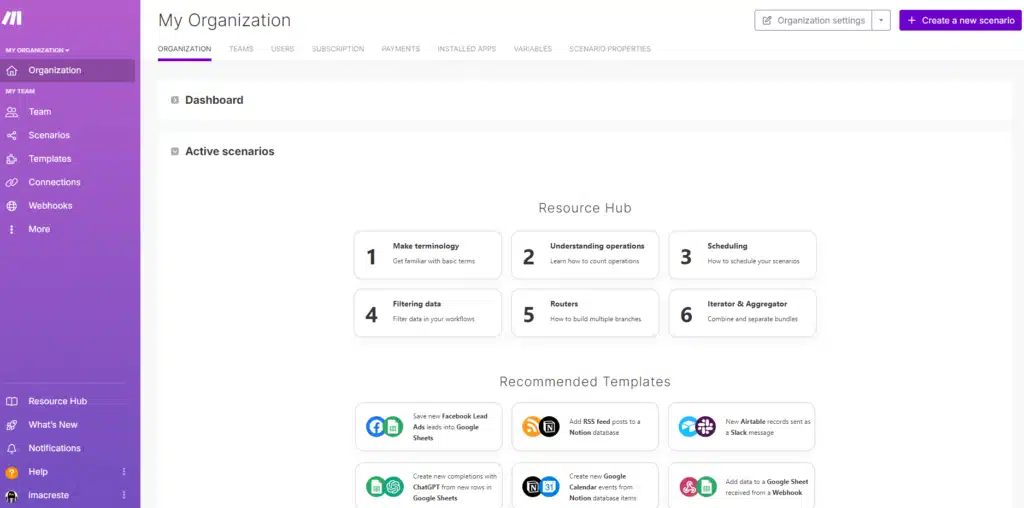
Al iniciar sesión en Make, nos encontramos con la página principal o Home, la cual nos ofrece una visión general de nuestra cuenta y acceso a las principales funcionalidades. Vamos a revisar el menú lateral izquierdo que es donde esta lo más importante.
Información sobre una organización
En la parte superior de la pantalla, se encuentra la pestaña «Organización» (Podemos dar de alta varias organizaciones desde nuestro perfil abajo a la izquierda). Al hacer clic en ella, se despliega un menú con diversas opciones, siendo la primera el Dashboard.
Organization / Organización
-> Dashboard
Esta sección es esencial para gestionar Make, ya que proporciona información clave para el control diario y la administración de nuestro plan.
- Contador de uso: El Dashboard cuenta con un monitor que muestra el número de operaciones realizadas en Make, permitiéndonos llevar un control sobre el uso de la plataforma y asegurarnos de no alcanzar el límite de nuestro plan.
- Plan actual, precio y operaciones contratadas: En un recuadro a la izquierda, se muestra el plan que tenemos contratado, su coste mensual y el número de operaciones incluidas.
- Operaciones disponibles, renovación y fecha: Esta sección indica las operaciones restantes para el mes, la frecuencia de renovación de la suscripción (por ejemplo, mensual) y la fecha exacta en la que se reiniciará el contador de operaciones.
- Escenarios activos: El Dashboard también informa sobre el número de escenarios activos en nuestra cuenta, es decir, las automatizaciones en funcionamiento. Las cuentas gratuitas tienen un límite en la cantidad de escenarios activos simultáneamente.
- Transferencia de datos: Incluye un contador de transferencia de datos, que muestra la cantidad de información intercambiada entre aplicaciones conectadas en nuestros escenarios. Al igual que con las operaciones, el límite de transferencia de datos depende del plan contratado.
En la parte superior de la pantalla, se encuentra la pestaña «Organización». Al hacer clic en ella, se despliega un menú con diversas opciones, siendo la primera el Dashboard.
-> Escenarios activos
Justo debajo del Dashboard se encuentra la sección «Escenarios Activos», donde al hacer clic se despliega una lista con todos los escenarios que están actualmente en funcionamiento en nuestra cuenta.
-> Explore
La sección «Explore» nos da acceso a una biblioteca de plantillas creadas por otros usuarios de Make, brindándonos ejemplos de automatizaciones que podemos usar como inspiración para nuestros propios proyectos.
Teams / Equipos
La pestaña «Teams» nos permite crear y administrar equipos dentro de Make. En las cuentas gratuitas, solo se puede tener un equipo, pero en los planes superiores es posible crear varios equipos para organizar mejor los escenarios y usuarios según los proyectos o áreas de trabajo.
Users / Usuarios
En la versión gratuita de Make, la gestión de usuarios se lleva a cabo desde la pestaña «Users» en el menú lateral. Desde esta sección, podemos invitar nuevos usuarios a la cuenta, eliminarlos y asignarles distintos roles, como «Owner», «Admin», «Member», entre otros.
Subscription / Suscripción
La pestaña «Subscription» nos permite revisar los detalles de nuestra suscripción actual, como el tipo de plan, precio y número de operaciones. Desde esta sección, también podemos cambiar de plan o cancelar la suscripción.
Payments / Pagos
La pestaña «Payments» nos muestra un historial de los pagos que hemos realizado en Make, incluyendo la fecha, estado, método de pago y monto. Es útil para consultar información sobre nuestras facturas.
Installed Apps / Apps instaladas
La sección «Installed Apps» está dirigida a desarrolladores que desean integrar aplicaciones personalizadas en Make. Estas pueden ser programas creados por ellos mismos o adquiridos de terceros.
Variables
La pestaña «Variables» nos permite crear variables globales dentro de Make. Estas variables son útiles para almacenar información que queremos reutilizar en diferentes escenarios. Por ejemplo, podemos guardar un dato que necesitemos usar en varios escenarios.
Scenario Properties / Propiedades del escenario
La sección «Scenario Properties» está diseñada para empresas que necesitan un control sobre una gran lista de escenarios.
Team / equipo
Dentro de la pestaña «Team» en el menú lateral, encontramos opciones específicas para la gestión de nuestro equipo:
- Dashboard del equipo: Este panel muestra información similar al Dashboard principal, pero se centra en las operaciones y la transferencia de datos de los escenarios de nuestro equipo.
- Gestión de usuarios: Similar a la sección «Users» en la pestaña «Organización», aquí podemos administrar los usuarios que pertenecen a nuestro equipo.
- Opciones de notificación: En esta área, podemos activar o desactivar las notificaciones que recibimos sobre los escenarios de nuestro equipo. Por ejemplo, podemos elegir ser notificados cuando un escenario se ejecute correctamente o falle, entre otros eventos.
- Variables: Al igual que en la sección «Variables» general, aquí podemos crear variables que solo estarán disponibles para los escenarios de nuestro equipo.
Scenarios / Escenarios
La pestaña «Scenarios» es el centro de trabajo para la creación, edición y gestión de nuestras automatizaciones. Desde aquí, podemos:
- Gestión de escenarios: Aquí encontramos una lista de todos los escenarios que hemos creado. Podemos activar, desactivar, eliminar o clonar cada uno con un solo clic.
- Control de activación, desactivación, eliminación y organización: Make nos permite gestionar el estado de nuestros escenarios, activándolos o desactivándolos según sea necesario. También podemos eliminar los escenarios que ya no necesitamos o clasificarlos en carpetas para una mejor organización.
- Entrar en un escenario: Un escenario en Make sigue la lógica de un proceso con un inicio, un desarrollo y un final. En este proceso, definimos una «entrada» (la información inicial del escenario), un «proceso» (las acciones que se ejecutan con esa información) y una «salida» (el resultado final obtenido).
Templates / Plantillas
La pestaña «Templates» nos permite acceder a una biblioteca de plantillas creadas por otros usuarios de Make. Estas plantillas pueden ser utilizadas como punto de partida para desarrollar nuestros propios escenarios.
Connections / Conexiones
La pestaña «Connections» en Make es una de las herramientas más poderosas disponibles. Permite vincular nuestra cuenta con diversas plataformas y servicios, lo cual facilita la automatización de tareas que implican múltiples aplicaciones.
Conectividad a Google, Meta, OpenAI, WordPress y servicios como Eleven Labs, Linkedin, Microsoft, etc. Algunas de las conexiones más utilizadas incluyen Google Sheets, Gmail, OpenAI (ChatGPT), WhatsApp (a través de Meta), Eleven Labs (para generación de voz), Linkedin y Microsoft.
Webhooks
La pestaña «Webhooks» en Make nos permite configurar webhooks dentro de la plataforma. Un webhook es una forma de recibir información en tiempo real desde otras aplicaciones. Básicamente, actúa como un servicio que está a la espera de eventos que ocurren en otras plataformas; cuando estos eventos se activan, desencadenan acciones automatizadas en Make. Por ejemplo, cuando recibes un mail en Gmail.
Keys / Llaves
La pestaña «Keys» en Make facilita la gestión de las claves de API que utilizamos para conectar la plataforma con otros servicios. Estas claves son esenciales para autenticarnos en las APIs de los servicios externos.
- Identificación única: Cada conexión a una API requiere una clave única que identifica nuestra cuenta en el servicio externo.
- Comunicación segura: Las claves de API permiten que Make se comunique de manera segura y autorizada con las APIs de otras plataformas.
Devices / Dispositivos
La sección «Devices» en Make facilita la conexión de dispositivos móviles a nuestra cuenta.
- Aplicación móvil: Make ofrece una aplicación móvil que podemos instalar en nuestro smartphone. Es importante destacar que esta aplicación está diseñada principalmente para recibir notificaciones sobre nuestros escenarios y activarlos manualmente, pero no para desarrollar nuevos escenarios, ya que no es muy usable.
- Interacción con escenarios: Además, mediante la aplicación móvil podemos enviar inputs a nuestros escenarios, convirtiendo nuestro smartphone en un dispositivo de entrada para la automatización de tareas.
Data Stores / Base de datos
La pestaña «Data Stores» nos permite crear bases de datos internas dentro de Make. Estas bases de datos nos permiten almacenar información estructurada que luego podemos utilizar en nuestros escenarios.
Data Structures / Datos estructurados
En la sección «Estructuras de Datos» podemos definir la configuración de las bases de datos que creamos en Make.
- Configuración de bases de datos: Aquí podemos especificar las columnas y los tipos de datos que contendrá nuestra base de datos.
- Formatos admitidos: Make soporta diversos formatos de datos como JSON, XML y CSV para adaptarse a diferentes necesidades de almacenamiento.
Custom Apps / Aplicaciones personalizadas
La pestaña «Custom Apps» está pensada para desarrolladores que desean integrar aplicaciones externas a Make.
- Integración de aplicaciones externas: Permite conectar Make con aplicaciones que no se encuentran disponibles en la biblioteca de conexiones predeterminadas.
- Uso de APIs: Para integrar una aplicación externa, es necesario que disponga de una API (interfaz de programación de aplicaciones) que Make pueda utilizar para establecer comunicación con ella.
Creando un escenario en MAKE
Un escenario en Make es esencialmente un flujo de trabajo automatizado. Podemos imaginarlo como un lienzo en blanco donde diseñamos nuestra automatización. Cada paso de este proceso se representa como un módulo dentro del escenario. Estos escenarios nos permiten integrar distintas aplicaciones y servicios en línea, automatizando tareas repetitivas y aumentando la eficiencia de nuestros procesos.

Elementos de un escenario
Cada escenario en Make consta de tres componentes fundamentales:
- Entrada (input): Este es el punto de inicio del escenario. Define el evento que activará la automatización. Puede ser la recepción de un correo electrónico, la creación de un nuevo registro en una base de datos o la llegada de un mensaje en WhatsApp, por mencionar algunos ejemplos.
- Proceso: Es la secuencia de pasos que se ejecutan una vez activado el escenario. Involucra la manipulación de datos, la interacción entre aplicaciones y la ejecución de acciones específicas para cumplir con los objetivos establecidos.
- Salida (output): Representa el resultado final del escenario. Puede ser el envío de un correo electrónico, la actualización de un registro en una base de datos o la generación de un nuevo archivo, entre otras acciones posibles.
En Make, un escenario está formado por módulos que representan los diferentes pasos de la automatización. Cuando abrimos el constructor de escenarios, nos encontramos con un lienzo en blanco y un botón con un signo «+», que nos invita a «Agregar un módulo». Al hacer clic en este botón, se despliega un menú con la lista de aplicaciones disponibles para integrar en nuestro escenario.
El primer módulo activará la automatización (trigger o disparador). Este módulo suele ser una aplicación que recibe información, como un formulario, un webhook o una integración con un servicio de correo electrónico.
Ejemplo
Podemos guardar los correos electrónicos en una hoja de Google Sheets. En este caso, el «trigger» o disparador serán los correos que recibamos.
Tipos de triggers
Podemos categorizar los disparadores en dos tipos:
- Proactivos (programados – Instant en Make): Estos disparadores activan la automatización de manera planificada, en intervalos regulares, como cada hora o cada día. Se refleja en Make con un icono de un reloj.
- Reactivos (instantáneos – Acid en Make): Estos disparadores activan la automatización de manera inmediata al recibir un evento, como la llegada de un correo electrónico, modificación de un excel o un mensaje en WhatsApp. Se refleja en Make con un icono de un rayo.
- Bajo demanda: Son aquellos que solo se ejecutan cuando le damos a ejecutar. Se refleja en Make con un icono de una flecha.



Interfaz de un escenario
Nombre del escenario
Al crear un escenario, es fundamental asignarle un nombre descriptivo. Esto nos facilitará identificar el escenario fácilmente en el futuro.
Opciones del escenario
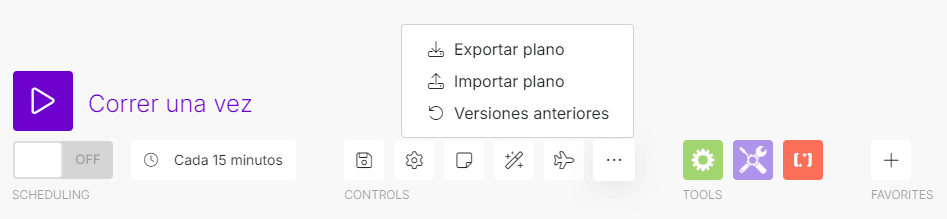
Dentro de la interfaz del escenario, dispondremos de un conjunto de controles para administrar su ejecución:
- Encendido y apagado: Permite activar o desactivar el escenario. Esto es lo que permite que un escenario comience a funcionar.
- Pruebas: Ofrece distintas opciones para probar el funcionamiento del escenario:
- Ejecución única (Run Once): Permite ejecutar el escenario una sola vez, ideal para comprobar su funcionamiento durante la fase de desarrollo.
- Programación (Scheduling): Permite programar la ejecución del escenario en intervalos regulares, como cada hora, cada día o cada semana.
- Pruebas de flujo: Permite visualizar el flujo de datos entre los módulos del escenario, mostrando el recorrido de la información y las acciones que se ejecutan en cada paso.
- Guardar (Save): Es importante guardar nuestro escenario para que los cambios que hayamos realizado se conserven. Para ello, debemos hacer clic en el botón «Save».
- Configuración del escenario: Dentro de la interfaz del escenario, también encontraremos un botón para acceder a la «Configuración del escenario». Aquí podemos ajustar diversos parámetros que controlan el comportamiento del escenario. Algunas de estas opciones incluyen:
- Tratamiento secuencial: Cuando está activado, el escenario ejecuta sus pasos uno tras otro, esperando a que cada módulo termine antes de proceder al siguiente. En caso de error en algún módulo, el escenario se detiene hasta que se solucione el problema.
- Datos confidenciales: Al activarse, todos los datos procesados dentro del escenario se almacenan de manera encriptada, garantizando su seguridad contra accesos no autorizados.
- Guardar ejecuciones incompletas: Si esta opción está activada, el escenario guarda la información procesada hasta el punto de fallo, permitiendo retomar la ejecución desde ese punto sin perder los datos previamente procesados.
- Añadir notas: Para documentar su funcionamiento o dejar comentarios para otros usuarios que trabajen en el mismo.
- Auto alinear: Organiza automáticamente la disposición de los módulos en el lienzo del escenario, mejorando la legibilidad del flujo de trabajo.
- Explicar el flujo (Explain flow): Visualiza el flujo de datos entre los módulos del escenario, mostrando cómo se procesa la información y las acciones en cada paso.
- Importar y exportar: Esta función es útil para compartir escenarios con otros usuarios.
Explicación de un módulo
Un módulo o nodo en Make es la representación gráfica de un paso dentro de un escenario. Cada módulo representa una acción que se ejecuta en una aplicación o servicio en línea.

Funciones de un módulo
Los módulos pueden realizar diversas funciones, como:
- Transformar datos: Modificar la información recibida, formatear texto, realizar cálculos o filtrar datos, entre otras acciones.
- Interactuar con datos: Permiten obtener, enviar y transformar información entre diferentes aplicaciones.
- Obtener datos: Un nodo puede recuperar información de aplicaciones como formularios, bases de datos o servicios web.
- Enviar datos: Pueden enviar datos a otras aplicaciones como correos electrónicos, hojas de cálculo o APIs.
Los módulos en un escenario se conectan entre sí mediante conexiones, las cuales facilitan el flujo de datos. Esta interacción permite que la información se transmita de un módulo a otro, posibilitando la ejecución secuencial de acciones.
Flujo de trabajo
El orden de los módulos en un escenario determina el flujo de trabajo. El primer módulo, como mencionamos anteriormente, actúa como el «trigger» o disparador del escenario. Los siguientes módulos se ejecutan en secuencia, siguiendo el orden establecido en el escenario.
Para añadir nuevos módulos al escenario, utilizamos el botón «+» (Agregar otro módulo).
Make ofrece una amplia variedad de aplicaciones que podemos integrar en nuestros escenarios. Cada módulo puede representar una acción específica en una aplicación, como enviar un correo electrónico, crear un nuevo registro en una base de datos o publicar un mensaje en redes sociales.
Secciones de un módulo
En Make, cada módulo está dividido en cuatro secciones principales que facilitan su configuración y uso dentro de un escenario:
- Botón «+» (Add another module): Este símbolo permite añadir otro módulo al escenario, estableciendo así la secuencia de acciones automatizadas. Al hacer clic en él, se abre la opción de seleccionar el tipo de módulo que deseamos agregar y establecer la conexión entre ellos para el flujo de datos.
- Mensajes de estado: Representados por un pequeño círculo, estos mensajes proporcionan información crucial sobre posibles errores de configuración o funcionamiento del módulo. Son indicadores visuales que ayudan a diagnosticar y corregir problemas rápidamente.
- Configuración del módulo: Al hacer clic en el icono de globo o burbuja del módulo, accedemos a su configuración detallada. Aquí podemos ajustar parámetros específicos del módulo para adaptarlo a las necesidades particulares del escenario que estamos creando.
Es desde donde se hacen las conexiones con otras plataformas como: Google Drive, Meta, OpenAI, WordPress, etc. Cada una se realiza de forma diferente, te recomiendo revisar la ayuda en línea que ofrece Make en cada módulo. - Configuración del «Trigger»: Esta sección está disponible únicamente si el módulo es el primero en el escenario. Permite configurar el disparador inicial que activará la automatización. Dependiendo del tipo de módulo y su función dentro del flujo de trabajo, aquí podemos definir cómo y cuándo se iniciará el proceso automatizado.
Entradas, salidas y procesamiento de datos (Bundles)
En Make, los datos circulan entre módulos, aplicaciones y sistemas, permitiendo que la automatización funcione de manera fluida y organizada. Para gestionar adecuadamente este flujo, es esencial comprender los conceptos de entrada (input), salida (output) y agrupación de datos (bundle).
Input: Se refiere a la información que recibe un módulo o escenario para ser procesada. Esta entrada puede consistir en datos como nombres, correos electrónicos, números de teléfono, archivos, fechas, entre otros.
Output: Es el resultado que produce un módulo o escenario después de procesar la información de entrada. La salida puede ser de cualquier tipo de datos, y muchas veces se presenta en una forma enriquecida o transformada en comparación con el input inicial.
Bundle: En algunos casos, los datos no se manejan de forma individual, sino como conjuntos relacionados llamados bundles. Un bundle agrupa múltiples datos en una sola unidad para que puedan ser procesados en conjunto, facilitando el manejo de información compleja en la automatización.

¿Por qué utilizar los Bundles?
Organización de datos complejos: Los bundles facilitan la estructuración de información cuando se maneja un conjunto de datos con varios atributos o propiedades, simplificando su gestión.
Eficiencia en la transferencia de datos: En lugar de enviar cada dato por separado, los bundles permiten transferir todos los datos juntos, optimizando así el flujo de la automatización.
Acceso simplificado a la información: Al agrupar datos relacionados en una misma estructura, los bundles hacen que sea más sencillo acceder y trabajar con la información en su conjunto.
Ejemplo: Supongamos que deseas registrar los asuntos de los correos electrónicos nuevos en una hoja de cálculo de Google.
- Selecciona una aplicación y un módulo desencadenador: Escoge una aplicación que inicie tu escenario (por ejemplo, “Gmail” con el módulo “Ver correos electrónicos”). Antes de esto, asegúrate de conectar tu cuenta de Google.
- Añade un módulo de acción: Conecta una segunda aplicación que realizará una acción sobre los datos obtenidos (por ejemplo, “Hojas de cálculo de Google” con el módulo “Agregar una fila”).
- Mapea los datos: Selecciona la información del primer módulo que quieres utilizar en el segundo módulo. Por ejemplo, elige el “Asunto” del correo electrónico para que se agregue a la columna “A” en la hoja de cálculo. En resumen, el primer módulo transfiere la información al segundo mediante un bundle de datos, del cual puedes seleccionar los elementos que necesites.
- Ejecuta el escenario: Para activarlo, haz clic en “Ejecutar una vez”. También puedes configurar opciones de programación para que el escenario permanezca activo y se ejecute automáticamente cada vez que recibas un correo nuevo.
JSON para manejar información
Los bundles gestionan la información en formato JSON. Aunque es fácil de entender, repasaremos algunos conceptos básicos para facilitar su comprensión.
JSON es, en esencia, un formato de texto que se asemeja a la estructura del código en diversos lenguajes de programación. A diferencia de un bloque de texto simple, JSON se adhiere a un formato predefinido con reglas específicas que facilitan su interpretación. Esta característica lo convierte en una opción ideal para almacenar y transmitir datos de manera organizada.
Estructura de JSON
La estructura de JSON se fundamenta en dos elementos principales:
Objetos: Los objetos en JSON se delimitan con llaves {} y tienen una colección de pares clave-valor. Es posible agrupar objetos dentro de otros.
Pares Clave-Valor: Cada par clave-valor representa un dato específico. La clave, o «key», actúa como un identificador o etiqueta, mientras que el valor, o «value», contiene la información asociada a esa clave. Las claves siempre van entre comillas dobles «» y se separan del valor por dos puntos :.
Ejemplo de JSON simple
{
"Título": "Película 1",
"Descripción": "Descripción de la película",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 7.6
}Estoy proporcionando datos sobre una película, y las claves siempre deben ir entre comillas. Sin embargo, si el valor es numérico no tendrá comillas. Además es importante poner los decimales con «.» en vez de la coma.
Ejemplo de JSON agrupado
{
Películas": [
{
"Título": "Película 1",
"Descripción": "Descripción de la película 1",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 7.6
},
{
"Título": "Película 2",
"Descripción": "Descripción de la película 2",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 5.6
},
{
"Título": "Película 3",
"Descripción": "Descripción de la película 3",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 6.3
}
]
}En este caso tenemos las películas agrupadas por «Películas» dentro de un «[«. De igual forma podríamos anidar diferentes agrupaciones:
{
Películas": [
{
"Título": "Película 1",
"Descripción": "Descripción de la película 1",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 7.6
},
{
"Título": "Película 2",
"Descripción": "Descripción de la película 2",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 5.6
},
{
"Título": "Película 3",
"Descripción": "Descripción de la película 3",
"Actores": "Actor 1, actor 2, etc.",
"Puntuación": 6.3
}
],
Personas": [
{
"Título": "Persona 1",
"Apellidos": "Apellido1 Apellido2"
},
{
"Título": "Persona 2",
"Apellidos": "Apellido1 Apellido2"
}
]
}En este caso, contamos con dos grupos: uno de películas y otro de personas. Esto se conoce como un array. Los arrays en JSON son colecciones ordenadas de elementos. En este ejemplo, el array «películas» contiene tres elementos, mientras que el array «personas» tiene dos elementos.
¿Qué son los Webhooks?
Los Webhooks son un método de comunicación entre aplicaciones que permite la transmisión de información en tiempo real.
Imagina dos aplicaciones que necesitan interactuar. Una de ellas puede «suscribirse» a eventos o cambios que ocurran en la otra. Cuando dichos eventos suceden, la aplicación suscrita recibe una notificación al instante mediante un Webhook.
Características clave de los Webhooks:
- Eventos específicos: Los Webhooks se activan con eventos concretos, como la creación de un nuevo cliente, un pedido, o la modificación de un registro.
- Notificaciones instantáneas: Cuando se produce un evento, la aplicación suscrita recibe una alerta en tiempo real.
- Comunicación en una sola dirección: La información fluye de forma unidireccional, desde la aplicación que envía la notificación a la que la recibe.
Ventajas de los Webhooks:
- Integración sencilla y flexible: Los Webhooks facilitan la conexión entre diferentes servicios y aplicaciones, mejorando la integración entre sistemas.
- Eficiencia: Los Webhooks eliminan la necesidad de que las aplicaciones revisen constantemente a otras en busca de actualizaciones, optimizando recursos y tiempo.
- Inmediatez: La notificación se envía en el momento del evento, lo que permite una reacción rápida.
Diferencias con una API: Una API no funciona de manera instantánea; debe ser consultada periódicamente. En cambio, un Webhook es automático y se activa en tiempo real cuando ocurre un evento específico.
Tipos de Webhooks
Existen diversos tipos de Webhooks según el método de envío y recepción de las notificaciones.
Dos tipos en Make:
- Mailhooks: Las notificaciones se envían como correos electrónicos a una dirección designada. Son sencillos de configurar y prácticos para integraciones básicas. El desencadenante para que se inicie el proceso, es enviar un email a un correo definido solo para ello. Por ejemplo:
z7qm0zyn2ffqs2romz2d6yxga9eqyfie@hook.eu2.make.com
Consejo: Dado que recordar este correo electrónico puede ser complicado, te sugerimos crear una dirección específica de tu empresa exclusivamente para esta automatización y redirigir los correos a esta dirección, que activará el proceso automáticamente. - Webhooks Web: Envía notificaciones a través de solicitudes HTTP hacia una URL específica de Make. Son altamente versátiles y se utilizan comúnmente en aplicaciones web. Por ejemplo, al crear un webhook web, obtendremos una URL que puede emplearse en una aplicación externa (como un ERP, una web, etc.) para enviar datos. Estos datos pueden probarse incluso desde herramientas como Postman. Al recibir los datos, Make activará automáticamente el escenario configurado.
Usar bases de datos en Make
Una base de datos es un conjunto organizado de información o datos estructurados, que generalmente se almacena de forma electrónica en un sistema informático. Estas bases de datos están diseñadas para facilitar el almacenamiento, la recuperación, la modificación y la gestión de datos. Son esenciales para diversas operaciones, que van desde el funcionamiento de sitios web y aplicaciones hasta procesos empresariales y análisis de datos.
Tipos de bases de datos:
- SQL (Structured Query Language): Se trata de bases de datos relacionales en las que la información se organiza en tablas compuestas por filas y columnas, interconectadas a través de relaciones predefinidas. Ejemplos destacados de bases de datos SQL incluyen MySQL, PostgreSQL y Microsoft SQL Server.
- NoSQL (Not Only SQL): Estas son bases de datos no relacionales que proporcionan una mayor flexibilidad en la estructura de los datos. Son capaces de manejar grandes volúmenes de información no estructurada, como documentos, archivos multimedia y datos provenientes de redes sociales. Algunos ejemplos notables son MongoDB, Cassandra y Redis.
- Datasets: Se refieren a conjuntos de datos organizados que pueden almacenarse en diversos formatos, como archivos CSV, JSON o XML. Los datasets son ampliamente utilizados para el análisis de datos, el aprendizaje automático y otras aplicaciones diversas.
En Make los datasets son una forma eficaz de almacenar y gestionar datos dentro de los flujos de trabajo. Permite crear datasets propios (Datastore), con una estructura de datos flexible, y también conectarse a datasets externos como Google Sheets o Airtable.
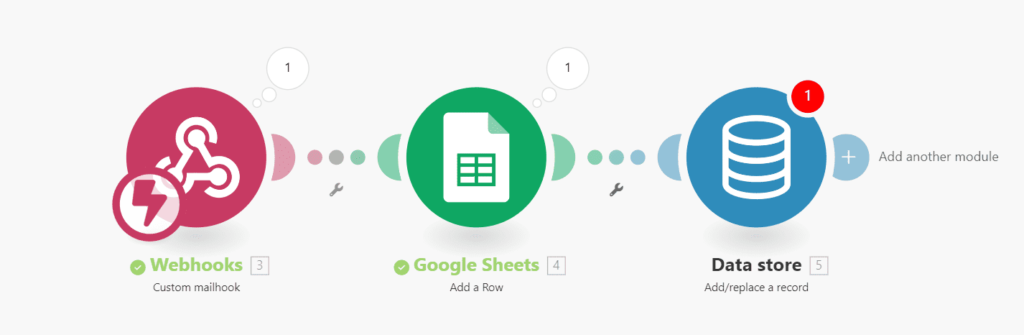
Control del flujo
El control de flujo, conocido como Flow Control, es una herramienta esencial en la automatización de procesos. Su principal función es regular el flujo del escenario, es decir, determinar la forma en que se ejecutará la automatización en función de diversas condiciones.
En esencia, el Flow Control nos permite responder a las distintas circunstancias que pueden surgir durante la ejecución del escenario. Para lograrlo, se basa en la lógica de los condicionales, que son estructuras que evalúan si una determinada condición se cumple o no.
Filtros en make
Los filtros son un componente esencial del Flow Control. Funcionan como control en el flujo del escenario, permitiendo que la automatización avance únicamente si se cumple la condición establecida en el filtro.
Por ejemplo, consideremos el escenario de la imágen de arriba. Si deseamos que la automatización solo procese aquellos emails que incluyan un correo concreto, podemos implementar un filtro que lo verifique. Si el correo no contiene ese mail, el filtro impedirá el avance y la automatización no seguirá ese camino.

Los filtros pueden variar en complejidad, desde los más simples, como el ejemplo anterior, hasta los más elaborados. Por ejemplo, podemos establecer un filtro que exija que el correo electrónico sea xxxx@gmail.com y, además, que contenga una imagen. En la imagen se pueden observar todas las operaciones disponibles: igual a, igual a (sin considerar mayúsculas y minúsculas), contiene, no contiene, entre otras.
Router
El Router es otra herramienta fundamental del Flow Control. Este módulo nos permite crear bifurcaciones en el flujo del escenario, dirigiendo la automatización hacia diferentes caminos según las condiciones que se cumplan.
El Router opera de manera secuencial, evaluando cada uno de los caminos o «branches» definidos en orden. La automatización seguirá todos los caminos en orden descendente.
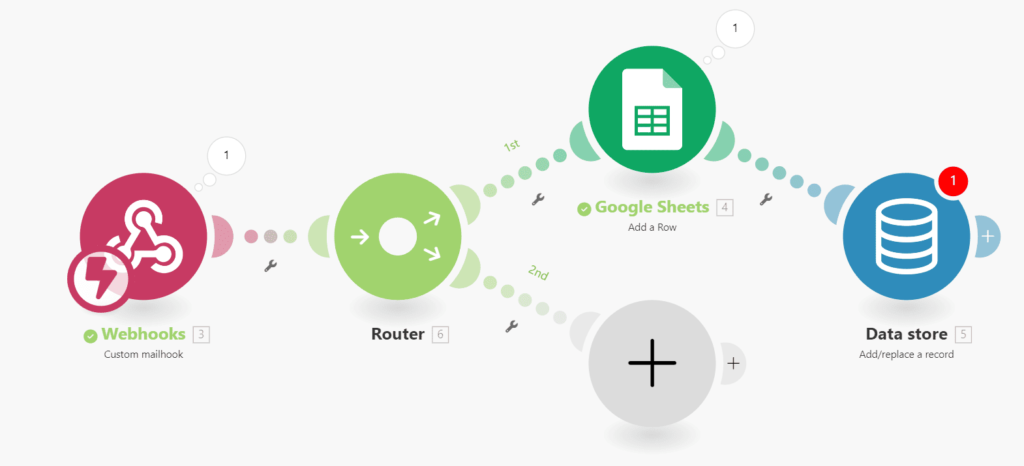
Siguiendo con el caso anterior, imagina que queremos guardar en Excel solo los correos que recibimos de un contacto específico, mientras que para el resto queremos realizar otra acción. En este caso, podemos añadir un router y, en la primera bifurcación, implementar un filtro basado en el correo electrónico.
Gestión errores (Error Handlers)
La automatización de procesos puede presentar errores en su ejecución. Por diversas razones, un escenario puede fallar en algún punto. Para prevenir que la automatización se detenga por completo, es recomendable utilizar Error Handlers.
¿Qué son los error handlers?
Los Error Handlers son módulos que se activan cuando ocurre un error en el flujo del escenario. Según el tipo de error y la estrategia que deseamos implementar, podemos elegir entre diferentes tipos de Error Handlers:
- Break: Detiene la ejecución del escenario por completo y notifica al usuario.
- Commit: Ignora el error y marca el escenario como completado, aunque no se haya ejecutado correctamente.
- Ignore: Desestima el error y continúa con la ejecución del escenario.
- Rollback: Detiene la ejecución del escenario, revierte los cambios realizados hasta el punto del error y notifica al usuario.
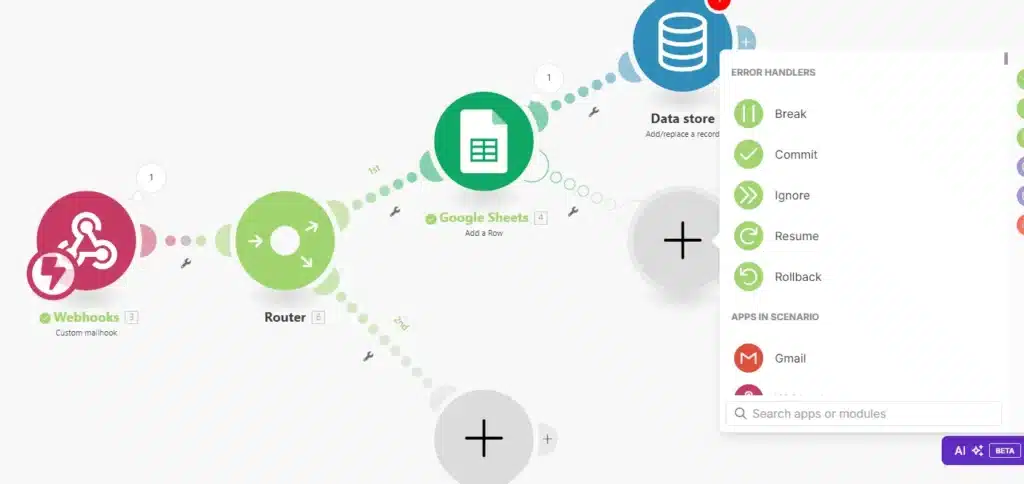
Ejemplo de uso de error handlers
Para activar un Error Handler, simplemente posicionamos el cursor sobre el módulo deseado y hacemos clic derecho. Luego seleccionamos «Add Error Handler» y definimos la acción que deseamos que se realice en caso de error.
Por ejemplo, supongamos que añadimos un paso de OpenAI a nuestro escenario para analizar mensajes y determinar si provienen de un cliente nuevo o de uno que necesita soporte. Si OpenAI está sobrecargado y ocurre un error, podemos manejarlo de esta manera.
Uso de variables y funciones en Make
Las variables son contenedores en la memoria que nos permiten almacenar datos para acceder a ellos en el futuro. Estos datos pueden ser el resultado de acciones previas o valores que definimos según nuestras necesidades.
Variables
Las variables son especialmente útiles cuando necesitamos guardar información que proviene de diferentes fuentes dentro de un flujo de trabajo. Por ejemplo, nuestro flujo puede recibir datos de diversas fuentes como correos electrónicos o archivos PDF. Utilizar una variable nos permite almacenar la información relevante sin importar su origen específico.
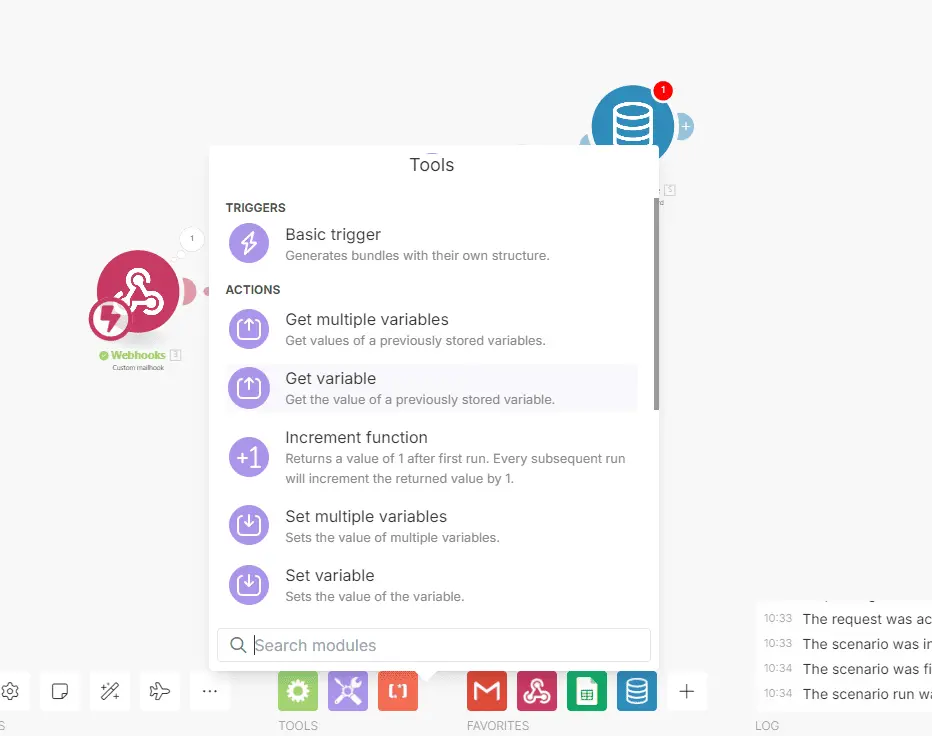
-> Ejemplo:
- Recibimos un correo electrónico.
- Utilizamos OpenAI para procesar información cómo una fecha de una reunión.
- Almacenamos la fecha extraída en una variable llamada «fecha_reunión».
- Aplicamos una función para formatear la fecha según el formato requerido.
- Guardamos la reunión en el formato requerido en nuestro ERP y en Google calendar.
Funciones
Las funciones son herramientas que nos permiten manipular información, ya sea cambiando su formato, adaptándola a nuestras necesidades o realizando operaciones matemáticas sobre ella. Las funciones de Make son similares a las funciones de Excel.
-> Tipos de funciones disponibles
Make ofrece una amplia gama de funciones, que pueden clasificarse en diversas categorías:
Modificar datos: Permiten modificar la información antes de usarla en otras acciones.
Funciones lógicas y de control de flujo en Make:
- Sumar, restar, multiplicar, etc.
- Pick: Selecciona un valor determinado.
- If: Ejecuta una acción si se cumple una condición.
- IfEmpty: Actúa si un valor está vacío.
- Switch: Permite ejecutar una acción u otra dependiendo de una condición.
- Omit: Elimina un valor específico.
Matemáticas:
- Random: Genera un número aleatorio.
- Promedio: Calcula el promedio de un conjunto de valores.
- Trunc: Elimina los decimales de un número.
- Ceil: Redondea un número hacia arriba.
- Floor: Redondea un número hacia abajo.
Texto:
- Lowercase: Convierte una cadena de texto a minúsculas.
- Capitalize: Pone la primera letra de una cadena de texto en mayúscula.
- Startcase: Pone la primera letra de cada palabra de una cadena de texto en mayúscula.
Fecha y hora:
- Timestamp: Devuelve la fecha y hora actual en formato Unix timestamp.
- Now: Devuelve la fecha y hora actual.
- Format date: Formatea una fecha en el formato deseado.
- Parse date: Convierte una cadena de texto a una fecha.
Creación de un escenario como ejemplo
Hasta ahora hemos explorado la interfaz de Make y comprendido qué implica la automatización NoCode y cómo aplicarla correctamente.
Vamos a proceder a desarrollar un sistema que interprete correos electrónicos y, según su contenido, clasifique la información como «NUEVO CLIENTE» o «SOPORTE A CLIENTES». Para lograrlo, utilizaremos un WebHook que esté atento a las entradas de correos electrónicos, un módulo de OpenAI para analizar el mensaje y finalmente un módulo de Google Sheets donde se almacenará la información.

Paso 1: Añadir WebHook cómo trigger
Empezamos añadiendo el módulo WebHook -> Custom mailhook y le asignamos un nombre. Al guardar, obtendremos una dirección de correo electrónico para la automatización. En mi caso, por ejemplo: 9p8r6tcizkbbo2u1iai4xrr6k0dyudnr@hook.eu2.make.com.
Todos los correos que lleguen a esta dirección serán los que inicien este escenario de automatización.
Paso 2: Conectando con OpenAI
Ahora procedemos a agregar el módulo de OpenAI. Para ello, haremos clic en el botón «+» para añadir un nuevo módulo y buscaremos «OpenAI». Luego seleccionaremos la opción «Crear una Completación / Create a Moderation (Prompt)» para enviar mensajes directamente al modelo GPT.
Crear conexión con OpenAI
El primer paso es conectarse con la API de OpenAI. Haz clic en el botón de Make y ponle un nombre a la conexión. Luego, dirígete al sitio web https://platform.openai.com/, ve al Dashboard, selecciona API Keys y genera una nueva API Key desde allí.
Para obtener el «Organization ID» que Make te solicita, puedes encontrarlo en el mismo sitio web, en el icono de herramientas ubicado en la esquina superior derecha.
Configurando OpenAI
- Selección del modelo: Vamos a escoger el modelo GPT que usaremos para procesar las respuestas. GPT-4 o GPT-4 mini son las opciones más potentes y recomendadas.
- Añadiendo mensajes:
- Rol «Sistema»: En este campo definimos un «pre-prompt» con instrucciones específicas para GPT. Por ejemplo, podemos indicar «Necesito que me clasifiques el mensaje recibido en si es «CLIENTE NUEVO» o «CLIENTE ANTIGUO», si no lo tienes claro etiquetado como «INDEFINIDO». No añadas más que la etiqueta por que es para una automatización y depende de esta tarea que funcione bien.«.
- Rol «Usuario»: Este campo representa el mensaje que recibimos del usuario desde Gmail. Para añadirlo, utilizaremos la opción «Contenido del Mensaje» y seleccionaremos «Text» del primer módulo.
- Rol «Asistente»: Este rol se emplea para contextualizar conversaciones más avanzadas con GPT. En esta ocasión, no será necesario utilizarlo.
- Tokens: Opcionalmente, podemos limitar la cantidad de tokens que GPT utilizará para generar la respuesta. Si establecemos el valor en «0», GPT utilizará todos los tokens disponibles.
Paso 3: Guardar la información en Google Sheets
Ahora procedemos a guardar la información. Para esto, es necesario contar con un Google Sheets preparado en nuestra carpeta de Google Drive, ya sea con cabeceras o sin ellas.
Para hacerlo, vamos a hacer clic en el botón «+» para agregar un nuevo módulo y buscar «Google Sheets». Luego seleccionaremos la opción «Añadir línea / Add a row».
Crear conexión con Google
El primer paso es conectarse con la API de Google. Haz clic en el botón de Make.
Configurando Google Sheets
Primero, vamos a especificar dónde se encuentra nuestro archivo de Excel, que en este caso está en Drive. Luego, seleccionaremos el archivo haciendo clic en «Click here to choose file» y elegiremos el nombre del fichero.
Una vez conectados con nuestro archivo, debemos especificar si tiene cabecera o no. Las cabeceras nos permiten identificar las celdas donde deseamos almacenar la información. Por ejemplo, si nuestra cabecera incluye Nombre, Email, Asunto, Texto y Tipo de Cliente, estas categorías se reflejarán en Make, facilitando la asignación de campos de manera más intuitiva.
Paso 4: Prueba final del escenario
Ahora, es momento de hacer pruebas.
- Para ejecutar el escenario, haz clic en «Run Once».
- Envía mensajes al email del WebHook. Envía uno que indique claramente que es de un nuevo cliente, otro que indique que es de un cliente antiguo, y uno más ambiguo para comprobar cómo ChatGPT clasifica correctamente los mensajes.
- Observa cómo Make procesa el mensaje y lo envía a OpenAI para generar una respuesta.
- Una vez procesado, vete a tu Google Sheets y comprueba el resultado.
Seguridad en make
Make ofrece una ventaja significativa en términos de seguridad en comparación con otras plataformas de desarrollo de asistentes. En lugar de interactuar directamente con el modelo de lenguaje, crea una infraestructura previa que procesa y filtra las solicitudes antes de que lleguen al modelo.
Como hemos visto, en Make es posible añadir filtros personalizados para proteger a nuestros asistentes de posibles ataques. Estos filtros actúan como guardianes, revisando las solicitudes entrantes y bloqueando aquellas que contengan patrones sospechosos o palabras clave asociadas a intentos de hacking.
Por ejemplo, si queremos evitar que alguien acceda a nuestros prompts, podemos añadir un filtro que bloquee consultas al chat que incluyan términos como «Python,» «JSON,» «admin,» entre otros. Este tipo de técnicas se emplean con frecuencia en ChatGPT, ya que proteger los prompts resulta casi imposible.
Usar GPTs personalizados en Make
No es posible llamar a los GPT personalizados de OpenAI desde Make, pero sí podemos utilizar las API Assistants. Esta herramienta permite una comunicación directa con GPT, el modelo de lenguaje que potencia ChatGPT, brindando un control más preciso.
Si quieres conocer su funcionamiento te dejo un tutorial de uso.
Preguntas frecuentes
¿Qué es Make.com y cómo funciona?
Make.com es una herramienta de automatización que conecta aplicaciones y servicios para automatizar tareas sin necesidad de programar. Funciona creando flujos de trabajo o «escenarios» que activan acciones basadas en eventos predefinidos, permitiendo ahorrar tiempo en tareas repetitivas.
¿Cuáles son los principales beneficios de usar Make.com en automatizaciones empresariales?
Los beneficios clave incluyen una mayor eficiencia operativa, reducción de errores humanos y la capacidad de conectar diversas aplicaciones para mejorar el flujo de trabajo. Make.com es especialmente útil para tareas repetitivas que requieren integraciones entre múltiples herramientas.
¿Es Make.com adecuado para empresas pequeñas o solo para grandes corporaciones?
Make.com es flexible y puede ser usado tanto por pequeñas empresas como por grandes corporaciones. Ofrece planes de precios variados y permite a cualquier usuario personalizar automatizaciones según las necesidades y el tamaño del negocio.
¿Cómo se comparan las automatizaciones de Make.com con las de otras herramientas como Zapier?
Make.com permite crear automatizaciones avanzadas con flujos de trabajo más complejos y detallados. Si bien Zapier es otra opción popular, Make.com ofrece una mayor personalización y capacidad para gestionar flujos más sofisticados, ideal para usuarios con necesidades específicas.
¿Se necesita experiencia en programación para usar Make.com?
No, Make.com está diseñado para usuarios sin experiencia en programación, aunque ofrece funciones avanzadas para quienes desean mayor personalización. Con su interfaz visual de arrastrar y soltar, es posible crear flujos de trabajo sin escribir una sola línea de código.
Conclusión
Make.com es una herramienta poderosa y accesible para cualquier negocio o profesional que busque optimizar sus procesos mediante automatizaciones. Con su interfaz intuitiva y capacidades avanzadas, facilita la creación de flujos de trabajo complejos que ahorran tiempo y mejoran la eficiencia.
Además, su flexibilidad permite que usuarios sin experiencia técnica configuren automatizaciones, mientras que los más avanzados pueden aprovechar su personalización.
Implementar Make.com en tu estrategia es una inversión en productividad y eficacia operativa, lo que te permitirá concentrarte en tareas de mayor valor.


