La rastreabilidad y la indexabilidad son dos conceptos cruciales que todo profesional de marketing de motores de búsqueda debe comprender. Si Google no puede rastrear e indexar tu contenido, no aparecerás en los motores de búsqueda.
Sin saber cómo funcionan ambos procesos, tu contenido puede desaparecer de los resultados de búsqueda de Google y no tendrás idea de por qué sucedió ni cómo solucionarlo.
¿Cómo puedo ayudarte a conseguir más clientes online?
- A corto plazo (Publicidad en Google, Facebook, e Instagram).
- A medio plazo (SEO local).
- A largo plazo (Posicionó tu web).
- Diseño página web, tienda online o landing page, si es necesario.
- Herramientas de seguimiento y medición.
- Diversificación: Marketing de contenidos, mail marketing, redes sociales, alta en directorios, etc.
- Automatiza con IA: Optimiza tareas y aumenta tu productividad. Certificación Máster IA by BIG School

Entonces ¿qué son?
El rastreo es la forma en que los motores de búsqueda descubren contenido nuevo y actualizado para almacenarlo en sus índices, de donde extraen los resultados de búsqueda. En resumen, lo encuentran rastreando y lo almacenan en sus índices (Bases de datos).
Los rastreadores de motores de búsqueda, también llamados arañas y bots, rastrean toda la información de una página web para saber y entender:
- El tema que trata.
- Calidad del contenido.
- Relevancia para determinadas palabras clave .
- El papel de la página en la arquitectura general del sitio web.
Es un proceso constante y los errores de rastreo e indexación ocurren constantemente, por eso es necesario saber cómo solucionarlos.
¿Qué es Crawlability?
La capacidad de rastreo (Crawlability) se refiere a lo fácil que es para los bots rastrear, navegar e indexar por tus páginas web. Puede tener una buena, regular o mala capacidad de rastreo, dependiendo de varios factores clave.
Los bots de motores de búsqueda pueden confundirse fácilmente si no se implementan ciertas prácticas recomendadas, como:
- Estructura de enlaces internos: Que cada página web tiene al menos un enlace interno que apunta a ella. Si una página no tiene enlaces internos se le llama página huérfana.
- Estructura de URL: URLs cortas, guiones para separar palabras, evitar cadenas largas de código, etc.
- Acceso al mapa del sitio XML: A través de Google Search Console o Bing Webmaster Tools. Los mapas del sitio hacen que el rastreo sea mucho más fácil para los robots de búsqueda.
- Velocidad de carga rápida.
- Un archivo robots.txt con el formato correcto: Facilita el rastreo a los buscadores.
- Evitar canibalizaciones: Evitar el contenido duplicado.
- Enlaces funcionales: Que se puedan rastrear, algunos enlaces con JavaScript no son rastreables. En ocasiones se usan para evitar que accedan a una página que no queramos indexar.
¿Qué es la indexación?
El índice de un motor de búsqueda es su base de datos de páginas web. Para que un sitio web aparezca en el índice de un motor de búsqueda, sus robots primero deben rastrear el contenido del sitio. Después de eso, un conjunto de algoritmos de búsqueda hace su magia para determinar si vale la pena posicionar el sitio web en los resultados de búsqueda.
El índice de Google es un catálogo gigante de páginas web que los rastreadores determinan que merecen ser incluidas en los resultados de búsqueda. Cada vez que un usuario busca una palabra clave, Google consulta su índice para determinar si tiene algún contenido relevante para mostrar en los resultados.
Problemas comunes de rastreo
Para abordar y resolver rápidamente estos problemas es necesario realizar auditorías técnicas de SEO. Además, podrá restaurar su contenido a los SERP más rápido, ya que sabrá por qué desapareció de repente.
Los problemas de rastreo más comunes son:
1: Mala estructura del sitio
Un rastreador puede llegar a confundirse tanto como un cliente potencial si su sitio no cuenta con una estructura y navegación lógicas.
Tanto los usuarios como los bots tienden a preferir sitios que tienen arquitecturas planas debido a lo fácil que es navegar en ellas. Plano quiere decir que cuanto más sencillo sea navegar y encontrar los contenidos, mejor.
Además, haz todo lo posible para incorporar las mejores prácticas de navegación, como las rutas de navegación (migas de pan), que muestran al usuario (y al bot) dónde se encuentran en la jerarquía de tu web constantemente.
Ejemplo, si un usuario busca en Google y acaba en tu web dentro de un producto, debería saber dentro de qué categoría se encuentra de forma rápida.
2: No hay suficientes enlaces internos
Ya he mencionado las páginas huérfanas, que son páginas web que no tienen enlaces internos, pero son solo un efecto secundario de no incluir suficientes enlaces internos.
Además de garantizar que todas las páginas más importantes se puedan descubrir a través de la navegación, los enlaces internos también:
- Hacen que la página web sea más fácil de rastrear y comprender para los bots.
- Puede mantener a los usuarios más tiempo en la web descubriendo nuevo contenido.
A los bots les encantan los enlaces internos porque:
- Los usan para descubrir otras páginas web.
- Comprender el contexto más amplio detrás de su contenido.
Por este motivo, debes intentar incluir enlaces internos en todas las páginas web que crees, especialmente en tus entradas informativas. Siempre que escribas una nueva entrada de blog, piensa en situaciones en las que puedas incluir enlaces a otras páginas.
Por ejemplo, supongamos que mencionas un tema de pasada sobre el que grabaste un vídeo hace unos meses. Añadir un enlace interno al vídeo dará a los lectores la oportunidad de obtener más información sobre el tema y dará a los rastreadores más contexto sobre tu site en conjunto.
El tiempo de permanencia en una web es un factor de calidad en la mayoría de casos (No todos, por que si la búsqueda es: Altura de Pau Gasol, se entiende que debe ser algo inmediato).
3: Enlaces rotos
Cuando un enlace está roto, significa que ya no apunta a su destino original.
Debido a esto, devolverá una página de error, normalmente un 404 No encontrado.
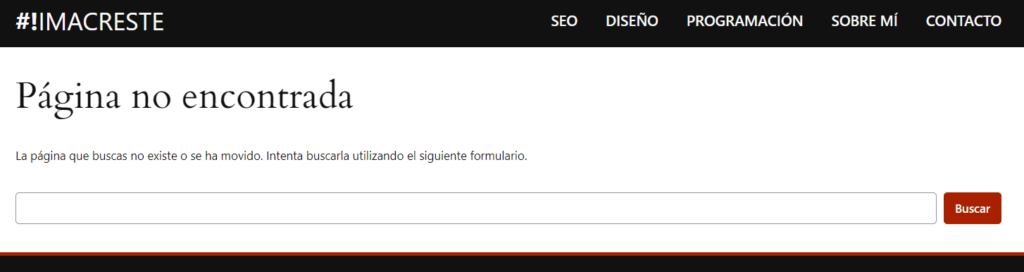
Las razones para que suceda suelen ser muchas pero normalmente se debe a contenidos que se eliminan y no se corrigen esos enlaces o a migraciones de página web.
Los enlaces rotos son muy peligrosos para el SEO porque provocan que desaparezca contenido valioso, por lo que es esencial estar atento a ellos. Screaming Frog es de gran ayuda en este sentido, ya que te permitirá saber si tienes enlaces rotos, entre otras muchas cosas.
3: No hay archivo robots.txt
Robots.txt es un archivo que indica a los rastreadores de motores de búsqueda a qué URL pueden acceder en la web y a cuáles no.
El propósito es evitar sobrecargar los motores de búsqueda como Google con demasiadas solicitudes de rastreo.
Además, es importante tener en cuenta que no todas las páginas de un sitio necesitan aparecer en los índices de los motores de búsqueda.
Como regla general, sólo debes permitir que los motores de búsqueda rastreen tus páginas más importantes , como tu página de inicio, tu contenido y tus páginas de productos o de destino.
Las páginas de administración, las páginas de agradecimiento y las páginas de inicio de sesión son ejemplos de páginas web que no necesitan aparecer en los resultados de búsqueda, ya que no proporcionan ningún valor a los usuarios.
Además, Google usa los presupuestos de rastreo: Los robots de los motores de búsqueda no funcionan por arte de magia y necesitan una gran cantidad de recursos para rastrear una página web. Para ahorrar energía, los motores de búsqueda como Google solo rastrean una cantidad predeterminada de páginas de un sitio.
Las páginas web más populares reciben presupuestos mayores, mientras que los sitios menos conocidos tienen que conformarse con menos.
4: No hay mapa del sitio XML
Un mapa del sitio XML (sitemap) proporciona una lista de URLs clara de la arquitectura de un sitio para los rastreadores, por lo que es muy importante crear uno.
Además, debes enviarlo directamente a Google Search Console (y a Bing Webmaster Tools si tu estrategia de SEO incluye Bing).
El informe de mapas de sitios de Google Search Console te permite ver tu mapa de sitio una vez cargado, incluidas las URL que los rastreadores de Google pueden ver actualmente, por lo que resulta muy útil.
5: Tiempos de carga lentos
Una velocidad de carga lenta puede ser un obstáculo para cualquier estrategia de SEO. Además de proporcionar una experiencia de usuario mala, lo que significa que no recibirás ningún favor en las clasificaciones.
PageSpeed es una herramienta que te permite obtener una vista previa del rendimiento de una página, y contiene sugerencias de mejora, por lo que vale la pena utilizarla.
6: Páginas web no optimizadas para dispositivos móviles
Desde 2017, Google utiliza la indexación mobile-first, lo que significa que clasifica primero la versión móvil de un sitio web. Y desde el 5 de Julio del 2024 Google prioriza el contenido móvil.
Como resultado, los propietarios de páginas web deben asegurarse doblemente de que sus páginas se muestren correctamente en teléfonos inteligentes y tablets.
La navegación web móvil ha sido la prioridad desde hace bastante tiempo, ya que actualmente representa el 61,79 % de todo el tráfico web.
Los diseños responsivos funcionan mejor, es decir, tu sitio web ajusta automáticamente sus dimensiones de acuerdo con el dispositivo del usuario.
Conclusión
Hay innumerables factores que afectan la capacidad de rastreo de un sitio web, y basta un solo problema para que tu contenido no aparezca en el índice de Google.
Por eso es tan crucial saber cómo identificar y resolver errores relacionados con el rastreo y la indexación.
Además, por si esto no fuera poco, mejorar aspectos como la usabilidad y velocidad, mejoran la calidad de las visitas y por ende, el posicionamiento.
¿Necesita ayuda para mejorar la rastreabilidad de su sitio web? Soy experto en SEO técnico.



Comentarios